
There are several ways to upload your data, depending on the size of the files:
HKU DataHub Interface
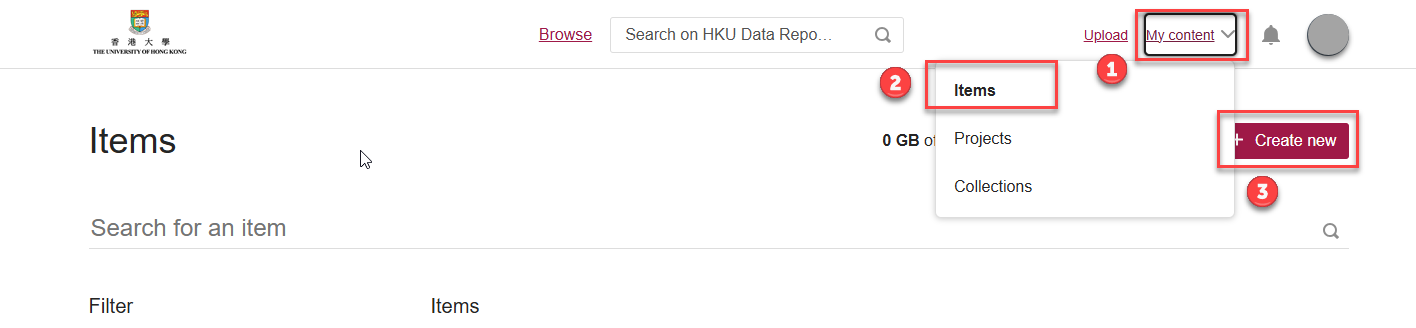
1. After you have signed in, at the top right corner, click on the “My content > Items” page and press the Create new button to start the uploading process.
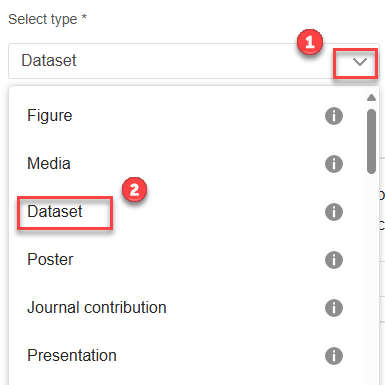
2. Select the appropriate item type for the file(s). Click on the little arrow to open the list, then select the item type from the list.
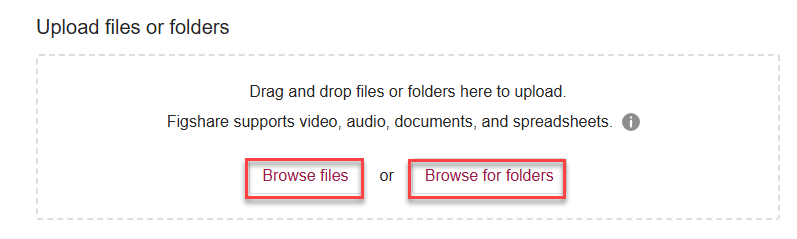
3. Click on “Browse files” or “Browse for folders” in the uploading box to select the file(s) or simply drag and drop the file(s) into the box.
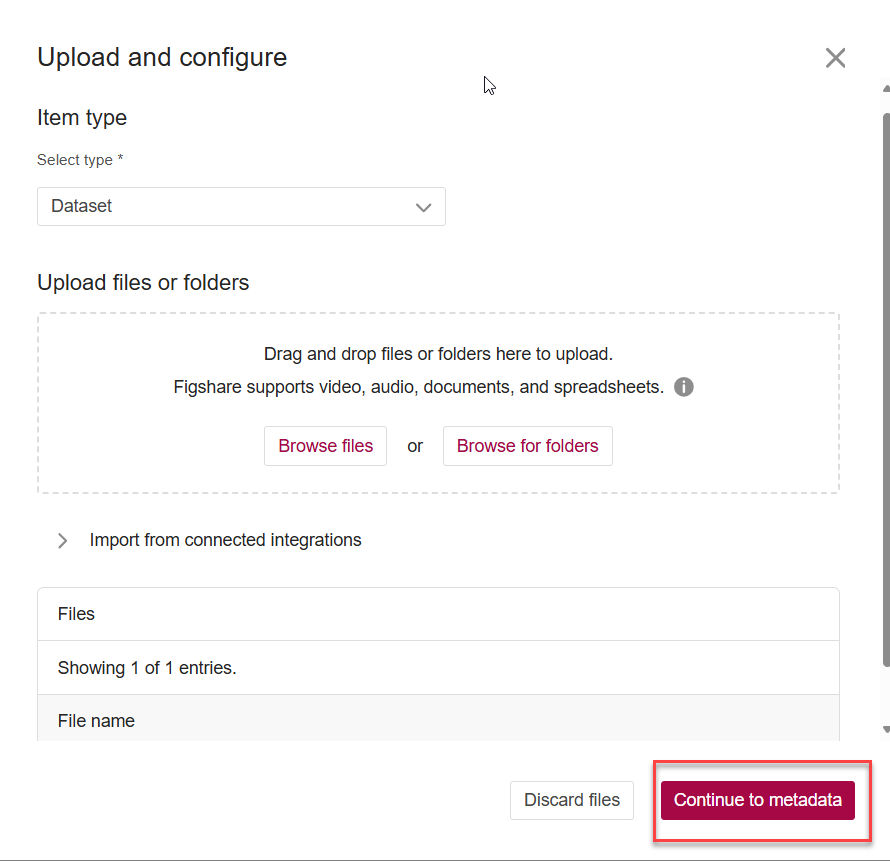
4. After you have uploaded all necessary files/ folders to the record, click the “Continue to metadata” to proceed.
5. In the “Authors” field, more than one author, or co-authors, could be added. You may drag the green boxes in order to rearrange the order or click on the cross button next to the author name for deleting it. If the author could not be found on the dropdown menu, click on “Add author details” for adding it manually.


6. Categories shall be selected from the dropdown menu. You are required to choose the primary category by clicking on the "Next" arrow, and select one or more sub-categories from the list by ticking the box(es).


7. Input the "keywords" that could specifically describe your data. Move your cursor to the input box and type the word. Please press on "Enter" after each word and the word will be saved.

8. Enter a "description" that introduce your data files / dataset / research project with details.

9. Add the funding information under “Funding” and multiple organizations could be added by clicking on “Add another”.

10. If you would like to link your dataset record with an article (e.g. peer-reviewed publication) which is related to your submitted dataset, or any other related materials (e.g. project website, online resources), you could input the identifiers such as DOI or URL under the section “Related Materials”.
First, click on "Manage materials".

Input the identifier, such as a DOI or an URL, under "identifier", and enter a title for this material, e.g. title of the linked journal article.

Select the identifier type from the dropdown box, and then select the relation type between the linked material(s) and the dataset. Click on "Add material" to add the related material. Multiple materials can be entered. You may continue to add the next material on the form. Click on "Done" when it is completed.
The entered materials will be listed at the bottom of the dataset record page. If you ticked the box "Show in linkout area", it will create an box on the right side of your dataset item record page which highlights the linkage.

You may refer to an example of a dataset record linked with external resources.
11. Select the appropriate "license" you wish to obtain for this dataset record. The default license will be CC BY-NC if no other preferred type of license is chosen.

12. Click on “Save changes”. You may wish to preview how your dataset record will look after publication by clicking on "Preview item".

13. At this stage, your data have been uploaded but not yet been publicly available. You may follow the steps stated in section Publishing an item under Publishing Data for making it permanently available.
*************************************************************************************************************************
Before publication, you are advised to review the below:
Submit data to DataHub without an account
DataHub now supports non-login submissions on a designated page that is configured allowing external users, who collaborate with HKU researchers in research projects, to submit contents or data files to DataHub without having a HKU DataHub or Figshare account. The page for submission can be accessed at http://datahub.hku.hk/submit.
Collaborations between HKU researchers and academics with individuals outside of the HKU community may frequently take place in projects conducted at HKU. As DataHub has access restrictions to internal members for data uploading and management, this page allows external members to submit their work to DataHub for collaborative projects easily without an institutional account at HKU.
Note: Please contact the HKU Research Data Services via Email-a-librarian (To: Research Data) if you would like to make a submission.
Submission Workflow
1. Access the page (http://datahub.hku.hk/submit) and get past the reCAPTCHA verification.
2. On the main submission page, select the group that your data will be submitted to from the drop-down list. Drag your file(s) to the uploading area on the browser or select the file for uploading by pressing the "Browse" button. You may upload multiple items.
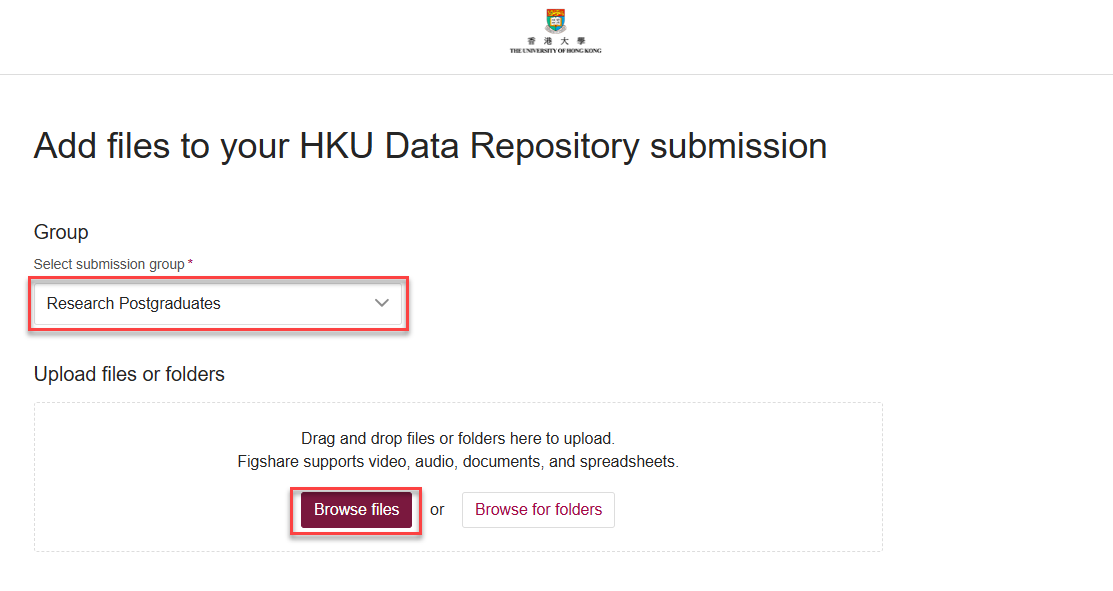
3. After uploading all files, click "Continue to metadata".
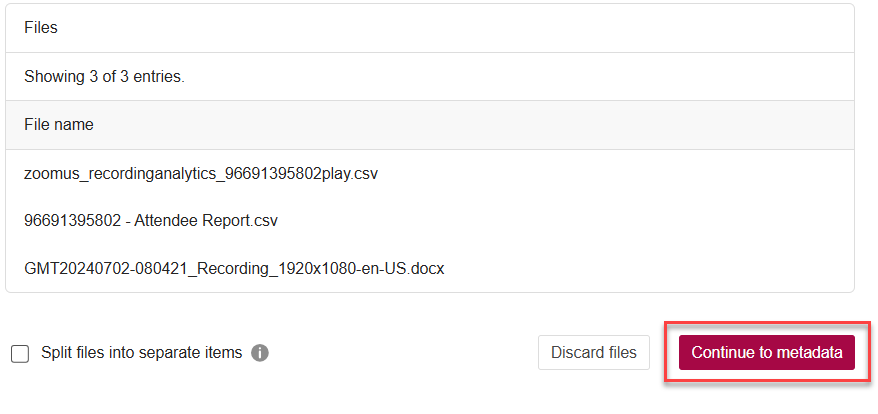
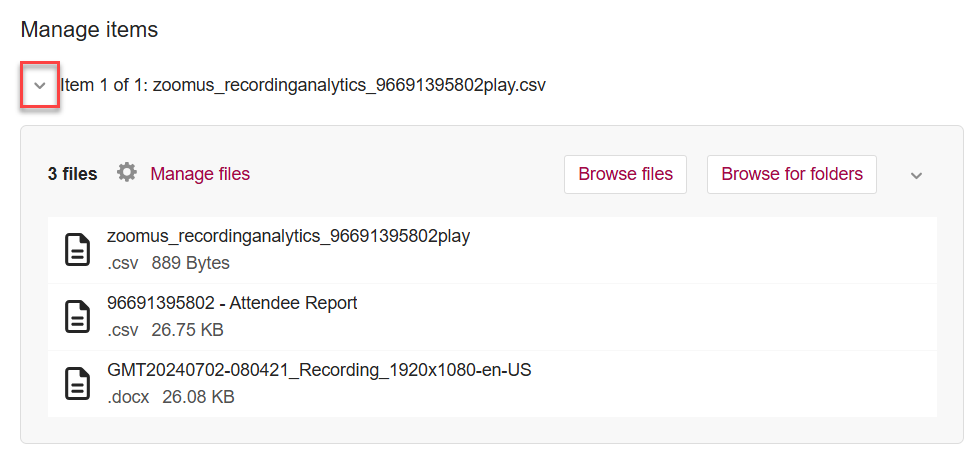
4.Click on the > under Manage items. Then, fill in all necessary metadata fields (i.e. Title, Authors, Description, License, Categories, Keywords, etc.).
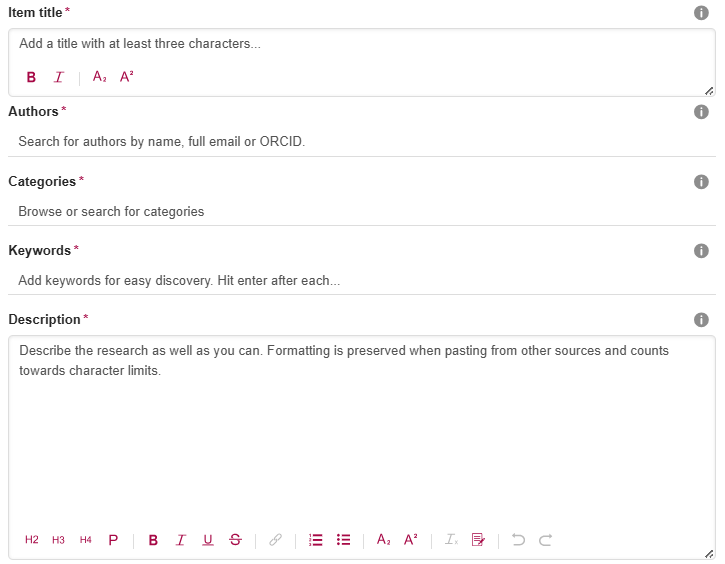
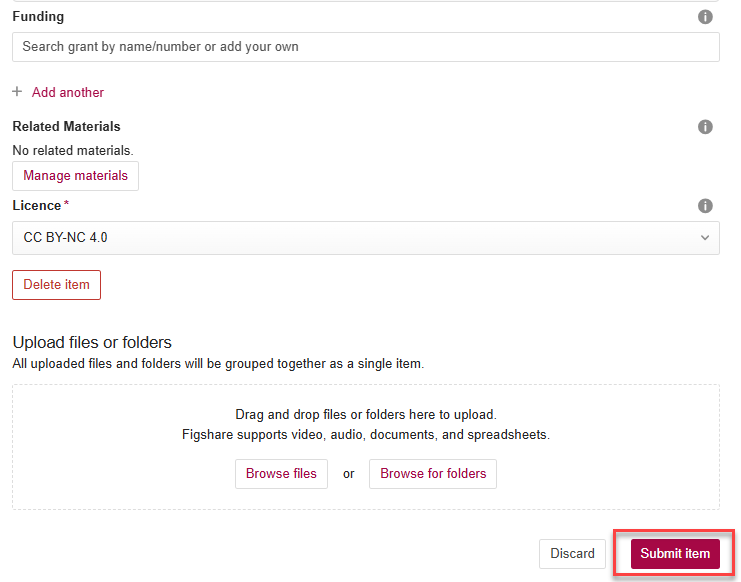
5. Scroll to the bottom and click on the “Submit item” button. You will be directed to an acknowledgement page with the message “Your submission was successfully sent”.
FTP Uploader allows you to easily and securely upload files in your account directly from your computer by using a secure FTP connection. To use this method, you need to install an FTP client like Filezilla (but any FTP client will work).
When you have successfully downloaded and installed Filezilla on your device, please refer to the below step-by-step guidelines on how to establish FTP connections between Filezilla and HKU DataHub, as well as how to upload files via Filezilla.
**You are recommended to break down your datasets into multiple zipped folders with a smaller folder size per each if you have a very large volume of data files.
**Only zipped folder (.zip) can be uploaded via FTP Uploader. Uploading unzipped folders will fail to transfer the files to DataHub.
Retrieve FTP Username and Password on HKU DataHub
Go to HKU DataHub and login with your HKU credentials. Click on “Integration” from the drop-down menu at the top right corner.

Mark down the “Username” for your account and press on “Generate Password” to retrieve the password for later use.

Establish Connection Settings
Open Filezilla, Select File > Site Manager…

Follow the instructions step by step in the below image:

First, create a "New site", rename it to "HKU DataHub" or any name that you could recognize it. On the right hand side of the panel (i.e. item 3-4), under the "General" tab, please follow and enter the below settings:
Host: ftps.figshare.com Port: 21
Protocol: FTP - File Transfer Protocol
Logon Type: Ask for Password
User: The username you copied from HKU DataHub in Step 1

Now, switch to the "Transfer Settings" tab, select Passive under "Transfer mode". When everything is set, press on the Connect button.

A pop-up window will be prompted to you and you are required to enter the Password that you copied from HKU DataHub in Step 1.

Press OK to proceed.
Start uploading your files
Please read the reminder notes (under the session “Before you begin”) from Figshare Help.
**Create ONE folder under the ‘data’ folder only. Please do not create any sub-folders under this newly created folder.
**You are recommended to break down your datasets into multiple zipped folders with a smaller folder size per each if you have a very large volume of data files.
**Only zipped folder (.zip) can be uploaded via FTP Uploader. Uploading unzipped folders will fail to transfer to HKU DataHub.


Tips: You are recommended to upload a testing text file to test the uploading flow before you actually upload your data files especially if they are very large in size. You can delete the testing file from your data record afterwards.
Step 4
Double check your uploading status and files uploaded
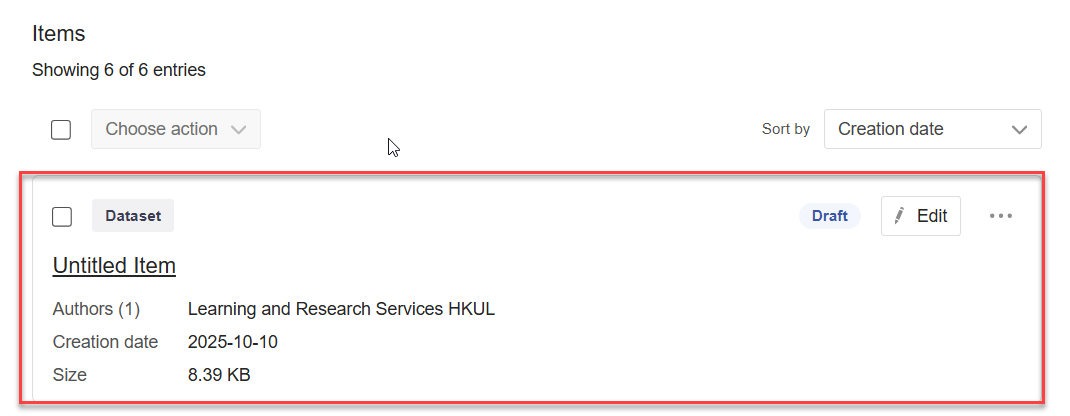
Return to HKU DataHub, if you have successfully uploaded any files onto the folder directory in Filezilla, an item record with the same name of your created directory will appear automatically on your “My Content > Item” page.
Whenever a file or a folder has been successfully uploaded via the FTP uploader, it will appear under this item record.
**Note: The item record does not appear if you haven’t uploaded any files under the new folder directory on Filezilla.
Step 5
Amend the metadata of this item record
Once you have uploaded all data files, enter the metadata onto the item record as per the requirements, including dataset title, author(s), dataset descriptions, item type, category, etc. (Refer to Step 3 in the upload via DataHub Interface guideline) Your item record will be ready for submission and publication once you have completed the metadata fields.
For Research Postgraduate student, please return and refer to Step 4 in the Submission Guide to complete the metadata requirements and proceed to the remaining submission steps.
GitHub
To connect Figshare with your GitHub account, you can set up in the Integration section, which is located in the dropdown menu at the top right corner next to your name. Next, select Connect to GitHub as shown below:

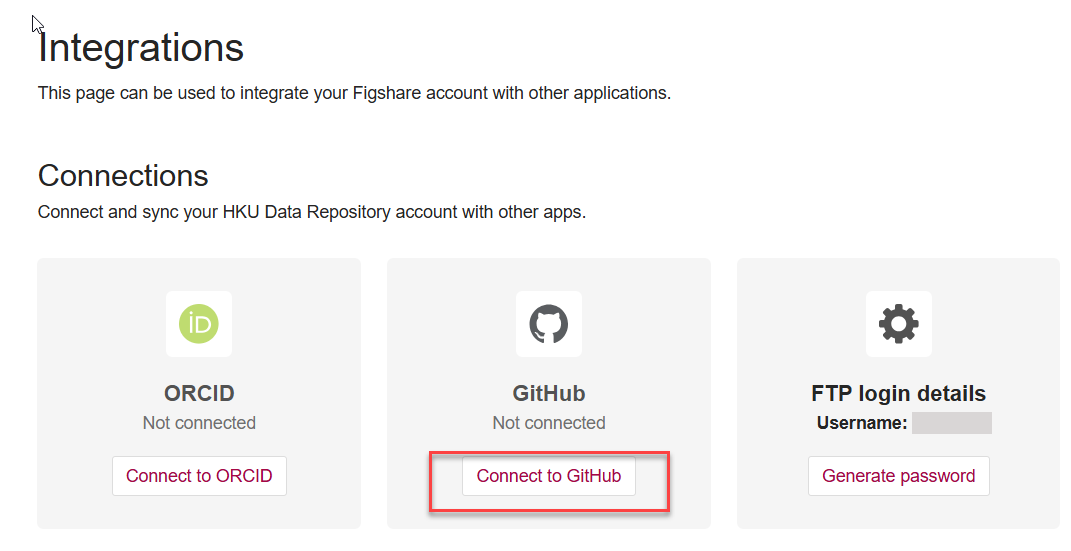
After signing in to your Github account, you will be able to authorize Figshare for integration.
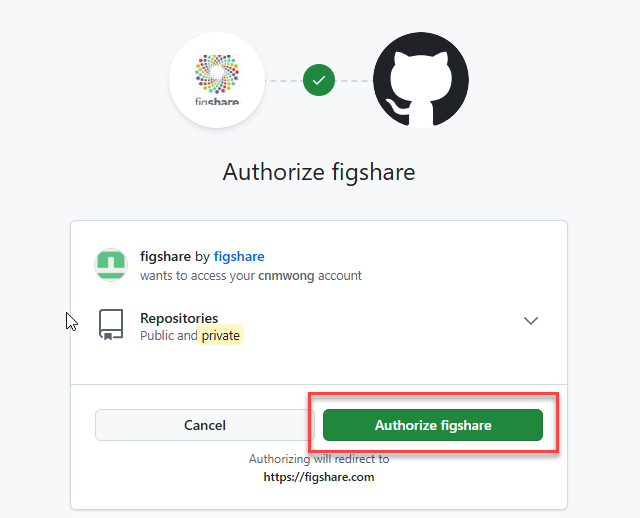
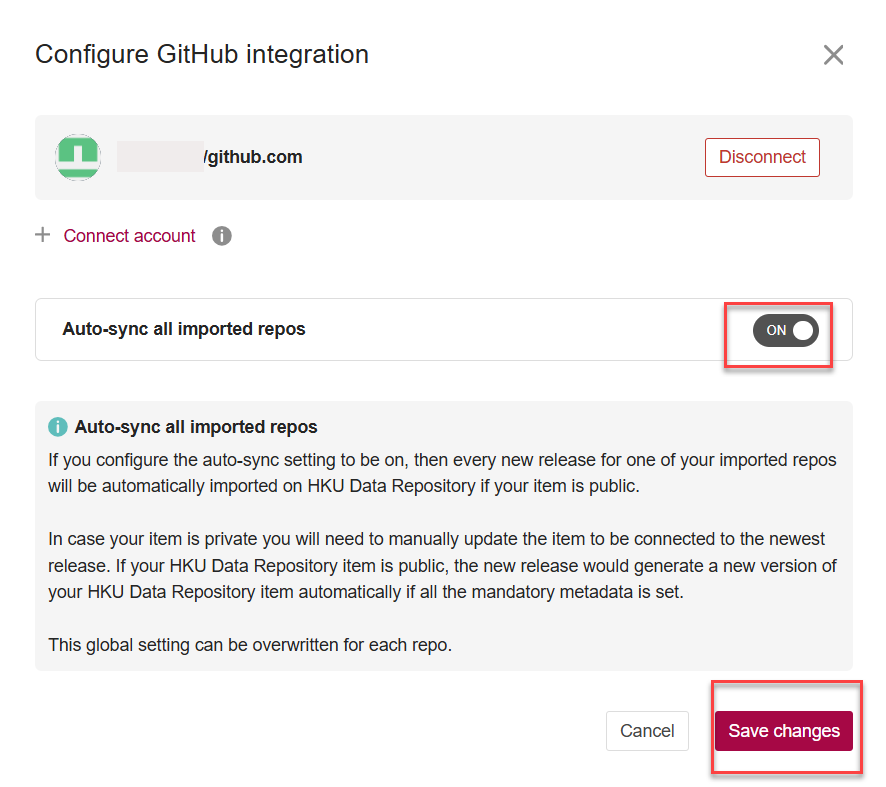
After the authorization, you can choose if you want to turn on the “Auto-sync all imported repos” feature.
If you configure the auto-sync setting to ON, Figshare will automatically update for every release (for each of your imported repos) and this will only occur if your data record on HKU DataHub is public. Each new release would generate a new version of your dataset record. Then, Click “Save changes” to save your settings.
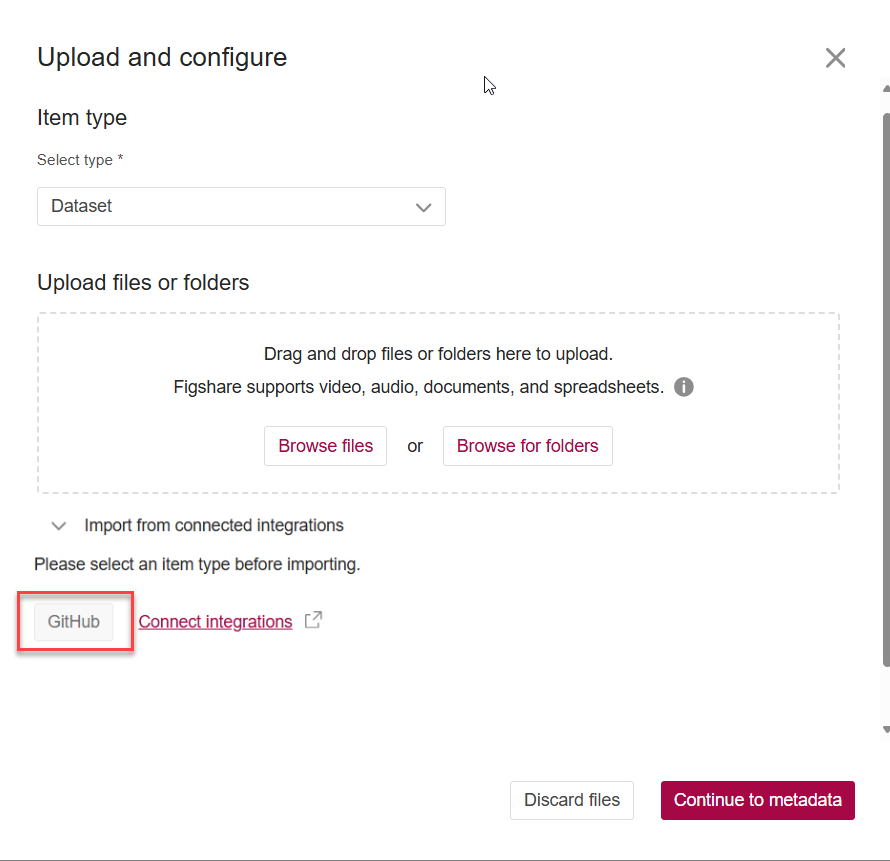
To start uploading data that were already deposited on Github, go to the "My content > Item" tab and click on the GitHub button as shown in the figure below..
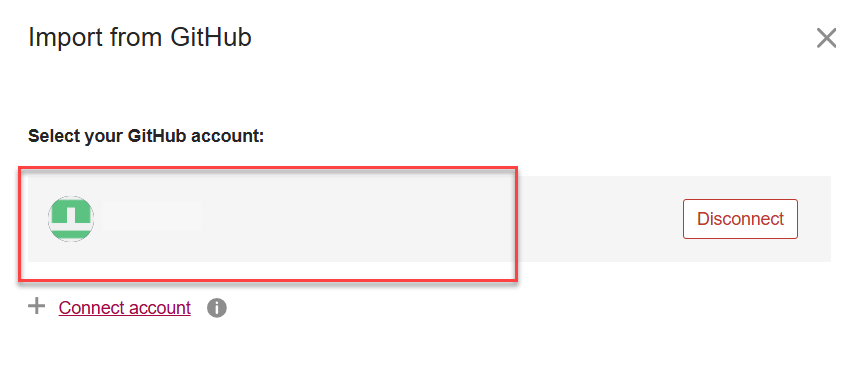
Then, you can start importing data files in your list of public repositories from GitHub:
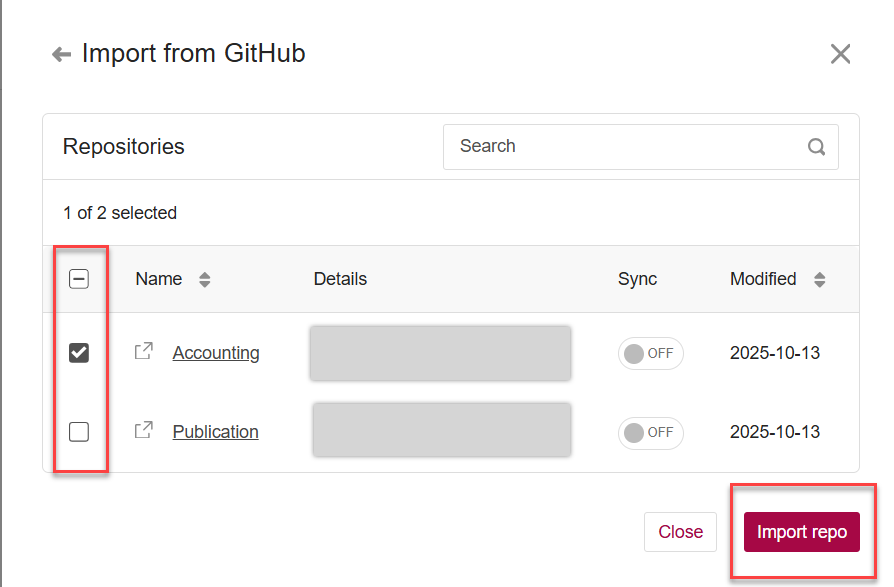
For more detials, please refer to the figshare article on how to connect Figshare with your GitHub account.
Figshare API
The Figshare API allows you to push data to Figshare, or pull data out. It can also create collections out of public content or build applications on top of the functionality.
Documentation on how to use Figshare's API can be found at https://docs.figshare.com/.
Restricted Access
There are occasions that you may wish to upload your data with access control conditions, especially for the sensitive data that conveys personal identifiers. The below will guide you through the steps required for setting up access restrictions to your files.
If your data contain sensitive, confidential or restricted data per the HKU Policy on Research Ethics, you are required to handle those data by means of either of the below two methods:
Upload the data under restricted access
Make and upload a version that anonymizes the data, for public access (with the approval of relevant IRBs or ethics committees)
Please refer to the "Restricted Access" section for a detailed step-by-step guide.
Linked Files
If your data is already retained in an external repository, you may wish to create an item record with the link directing others to where your data is stored.
Go to the “My Content > Item” page, click + Create new button, select an option from the Item type list, then click “Continue without uploading files” button.
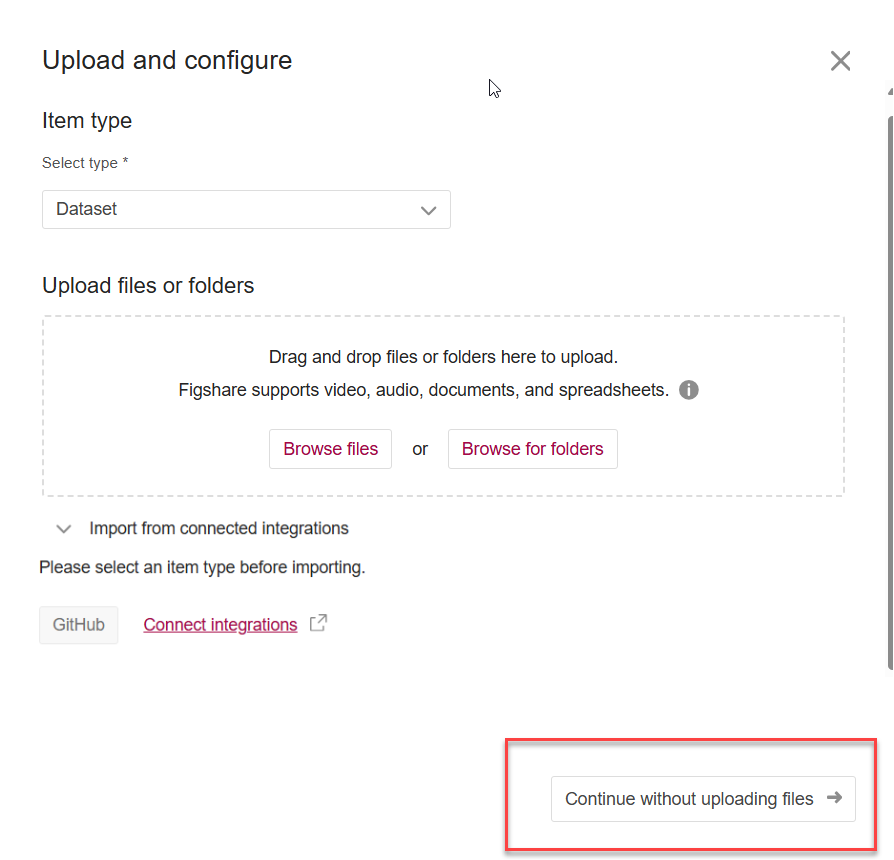
Instead of browsing or dragging any files, click the “Link to external files” button in the data uploading box. Copy and paste the link into the text box.
Note: This option is available only if you have not uploaded any files to the item.

If you would like to edit the link, you are required to remove it completely by clicking the cross symbol (Remove external link) and add a new one.

The link will be shown on top of the published metadata page as shown below. You can refer to an example of a linked file item.

Metadata Record Only
If your data are forbidden to be uploaded onto another repository owing to copyright issues, or the data are considered to be too sensitive to be uploaded (with valid justification), you may wish to create a metadata record only.
Go to the “My Content > Item” page, click + Create new button, select an option from the Item type list, then click “Continue without uploading files” button.
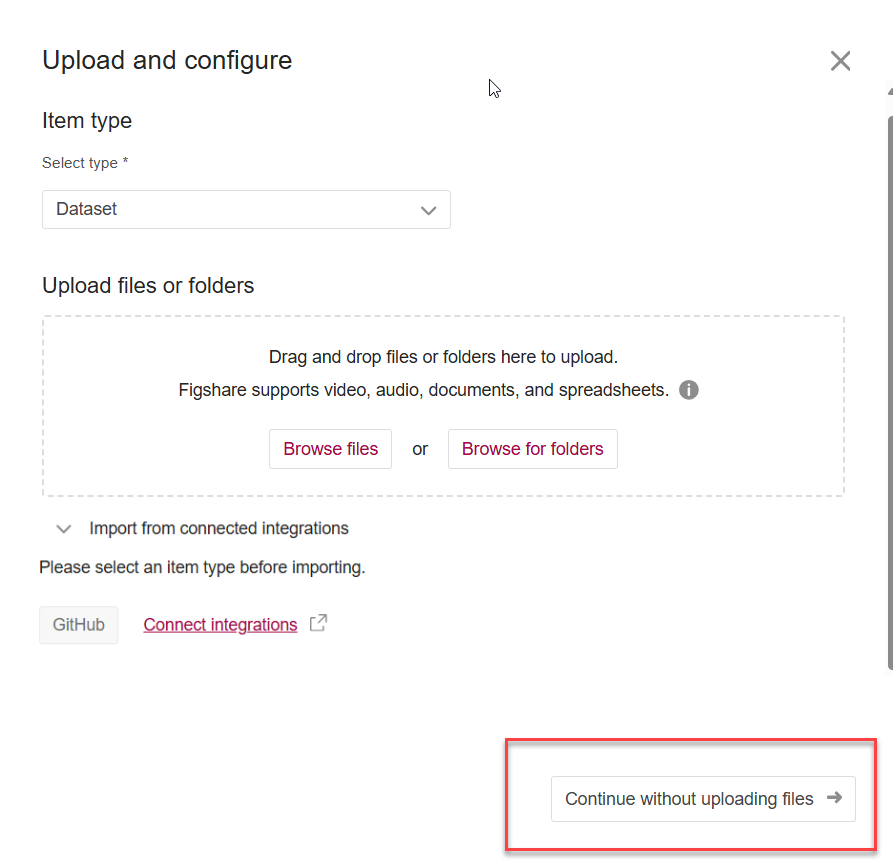
Without any file(s) being uploaded, select the “Set as metadata record” option in the data uploading box. Fill in the reason(s) for creating a metadata record only. Provide the access information if data are preserved in an external repository.

Once the item is published, the metadata record page will be publicly available with no file to be shown. You can refer to an example of a metadata record.

By publishing your research on DataHub, a DataCite DOI will be automatically allocated, which will enable your data to be cited using different citation methods.
However, if your data are not ready to be published yet, you may also reserve a DOI during the uploading process. It will only be active and citable when the item is published.
Click on “Reserve DOI” at the right side of the item details page.

Click on "Reserve". A DOI will then be generated immediately. It will be shown in a prompted box.

Press on the "Copy" button to copy the reserved DOI for future use, then close it.

The DOI information will be available on the right side of your screen. You may "disable DOI" only if the item is private and not yet published. Please note that the activated DOI cannot be disabled once the item has been published.

